Co-authored by Advika Jalan & Nitish Malhotra
The explosive growth of data and heightened interest in AI will only result in increased data engineering workloads. Against this backdrop, we outline the Metamodern Data Stack, which: (1) is built around interoperable open source elements; (2) uses technologies that have stood the test of time and continue evolving; (3) leverages AI at each stage of the data lifecycle; and (4) is partly decentralised. This is underpinned by a number of recent developments, ranging from Amazon’s launch of S3 Express One Zone (EOZ) to the open-sourcing of Onetable by Onehouse – all of which we discuss in greater detail in our note.
MMC was the first early-stage investor in Europe to publish unique research on the AI space in 2017. We have since spent eight years understanding, mapping and investing in AI companies across multiple sectors as AI has developed from frontier to the early mainstream and new techniques have emerged. This research-led approach has enabled us to build one of the largest AI portfolios in Europe.
We work with many entrepreneurs building businesses that enable enterprises to take advantage of AI. Through our conversations with practitioners and founders building in the data infrastructure space, we have identified a range of emerging technological trends that would support the creation of an AI-first data stack, which we call the Metamodern Data Stack.
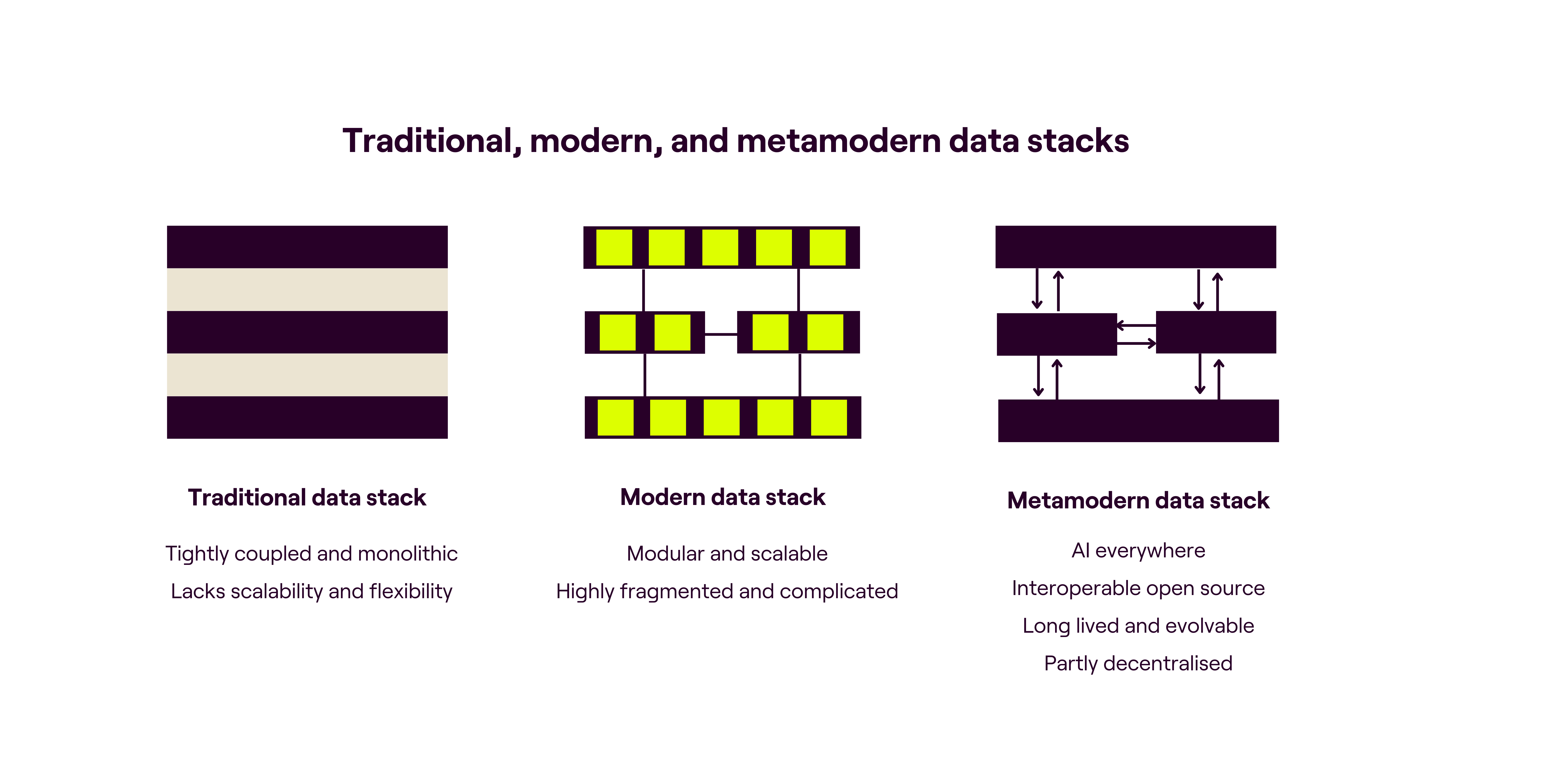
The TL;DR – key ideas underpinning the Metamodern Data Stack
The Prologue: The creation of the Modern Data Stack was accompanied by the proliferation of specialised tools, with poor levels of interoperability and integration between them. Additionally, many of these specialised tools often used proprietary formats, which worsened the vendor lock-in situation. This has led to a growing recognition of the need for interoperable open source software, and in particular reusable components.
The Present: Interoperable Open Ecosystems such as the one around Apache Arrow are gaining momentum, while late 2023 saw the launch of Interoperable Open Layers such as Onetable.
The Future: We expect more startups to build around Interoperable Open Ecosystems because it improves time to market, reduces undifferentiated heavy lifting, and allows them to instead focus on value-accretive activities. Meanwhile, we expect enterprises to adopt Interoperable Open Layers to unlock value across their tech stack.
The Prologue: Given the rapid innovation cycles where today’s hottest technology is obsolete tomorrow, practitioners are increasingly focused on longevity and evolvability – technologies that have or are likely to withstand the test of time, but are also getting better and more performant for emerging use cases. Object storage is a good example of Longevity and Evolvability, while SQL (the lingua franca for data since the 1970s) perfectly illustrates the idea of Longevity.
The Present: In November 2023, Amazon announced the launch of S3 Express One Zone (EOZ), a new object storage class that features low latency access (making the traditionally high-latency object storage c.10x faster). This should be beneficial to AI use cases that require fast access to storage. Meanwhile, new query languages which compile to SQL (such as PRQL and Malloy) continue gaining traction.
The Future: We believe startups can do two things: build their tech stacks on long-lived and evolvable technologies (such as object storage) and build solutions that evolve the long-lived (e.g. PRQL, Malloy). Particularly as AI/ML workloads increase, we expect more startups to build their primary storage on object storage, given the step change that Amazon S3 EOZ represents.
The Prologue: Enterprise demand for leveraging AI is increasing by leaps and bounds, and 70% of the work in delivering AI use cases is data engineering, making it imperative to enhance data engineering workflows. In particular, the ‘data-centric AI’ movement has renewed the focus on quality data.
The Present: Different ways of leveraging AI in the data lifecycle are emerging, e.g. improving data collection at the source by simulating image capture settings to optimise for quality, or automatically integrating image, text and video data by not only bringing them together, but also combining the context and narrative underpinning them.
The Future: We expect AI-powered data workflows to become more mainstream going forward, given various benefits such as automation, improved data quality, and better utilisation of unstructured data. Startups building in the data infrastructure space can consider adding AI-powered capabilities where it helps enhance workflows.
The Prologue: Data decentralisation is a growing trend, as growing workloads overwhelm centralised data teams, and regulations (such as those around data privacy and sovereignty) necessitate a distributed architecture. However, successful Data decentralisation would require us to overcome challenges with integration, interoperability and governance.
The Present: Many enterprises are implementing a hybrid version of the data mesh that involves a certain degree of centralisation (vs the more decentralised paradigm that characterises the data mesh i.e. no data warehouse). Independent of the data decentralisation trends, other technologies which would support “unification” in a decentralised environment are gaining traction e.g. data contracts, data catalogs and semantic layers.
The Future: We expect enterprises to adopt the “unification” technologies ahead of moving into a more decentralised structure, to ease the process and make the transition easier. As a result, we would expect more startups to build “unification” technologies to take advantage of this trend towards decentralisation.
Enterprises are reluctant to quickly replace mission-critical parts of their tech stack, given fears around disrupting business activities. Against this backdrop, a pragmatic approach would be to create solutions that let enterprises use their existing tools yet at the same time take advantage of the latest technologies.
The fundamental idea here is to focus on the existing and upcoming. For instance, a database gateway that decouples the app stack from the database engine wouldn’t just work with what is legacy and new as of today – it would also look at today’s latest technologies that will become obsolete in the future and provide a way to work with that alongside successor technologies. That’s why we believe pragmatism is a good starting point.
Taking a deeper dive into each of the key themes…
Interoperability and Openness
As we moved away from the tightly-coupled, monolithic models of the traditional data stack to the modularity of the modern data stack, this was accompanied by the proliferation of specialised tools, with poor levels of interoperability and integration between them. Additionally, many of these specialised tools often used proprietary formats, which worsened the vendor lock-in situation. This has led to a growing recognition of the need for interoperable open source software, and in particular reusable components. While the quest for interoperability isn’t new, it becomes all the more critical to achieve this to support growing AI workloads – and certain recent developments caught our attention.
For instance, at least 40% of Databricks customers use Snowflake, and vice-versa, despite the growing overlap between the two solutions as they race to be the primary choice for supporting AI workloads. However, they use different open source table formats – Databricks uses Delta Lake and Snowflake supports Iceberg. Although Databricks introduced UniForm (which automatically generates Iceberg metadata asynchronously, allowing Iceberg clients to read Delta tables as if they were Iceberg tables), this isn’t a truly bidirectional solution for interoperability between Delta Lake and Iceberg. Adding further complexity is the popularity of other formats, such as Hudi, and the emergence of newer ones, such as Paimon. This led to the creation of Onetable (open sourced in November 2023 by Onehouse), which supports omni-directional interoperability amongst all these different open table formats with the aim of creating a vendor-neutral zone.
Generally speaking, we see two main open source interoperability paradigms:
- Interoperable Open Ecosystem, which can be thought of a type of “vertical interoperability”, where open source components at different “levels” e.g. Parquet at storage level, Arrow at memory level, DataFusion at query engine level and Flight at network level are all highly compatible with each other.
- Interoperable Open Layer, which can be thought of as a type of “horizontal interoperability,” is an open source layer that sits atop different non-interoperable open source components at the same level to create interoperability e.g. Delta Lake, Iceberg and Hudi are all open table formats, so they are on the same level, but they aren’t directly interoperable with each other, which is where Onetable acts as the Interoperable Open Layer.
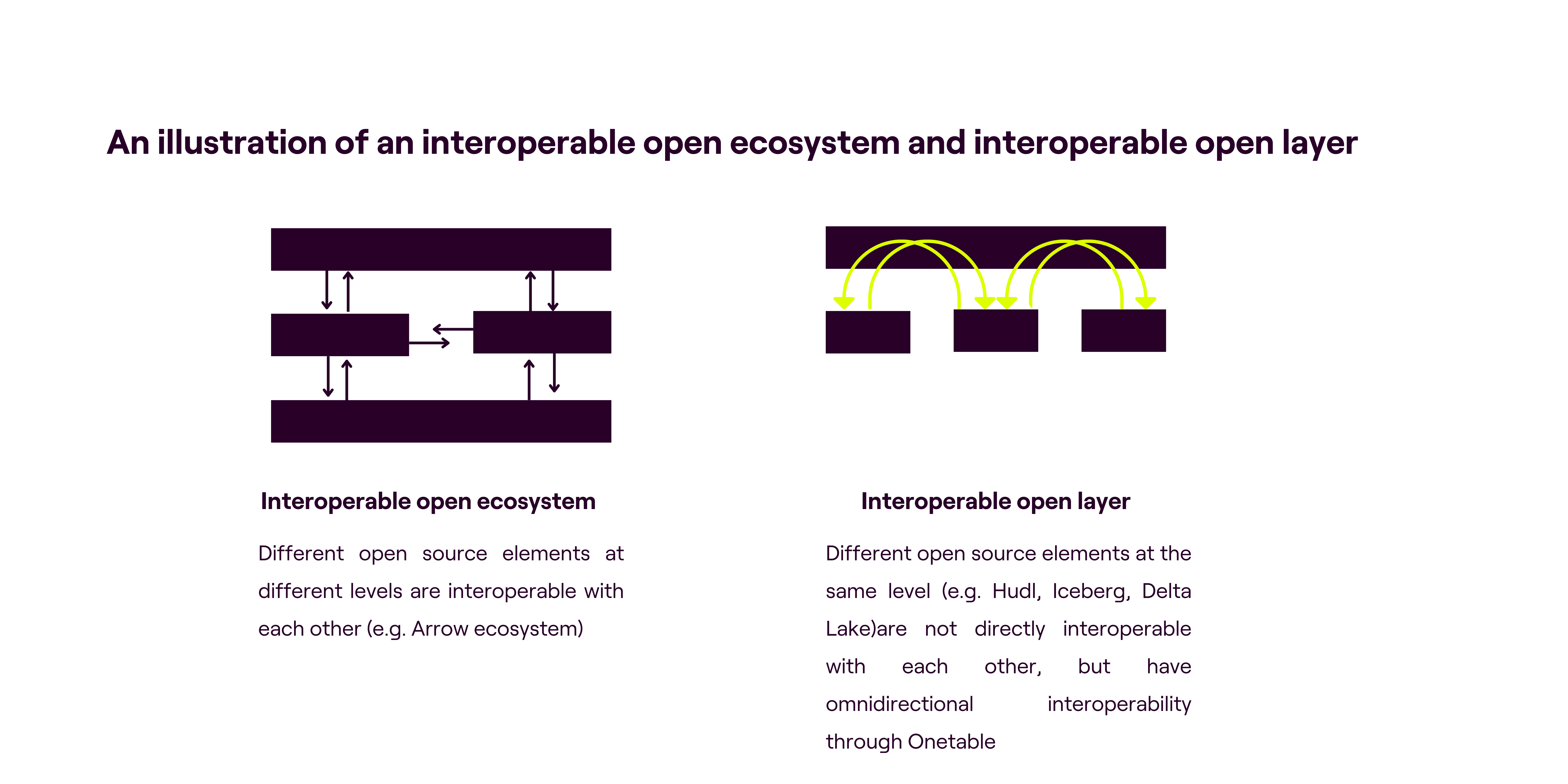
We illustrate the Interoperable Open Ecosystem through the example of Apache Arrow, an open source in-memory columnar format. Arrow is language agnostic (so systems written in different programming languages can communicate datasets without serialisation overhead) and creates an interoperable standard. Without standardisation, every database and language would implement its own internal data format, resulting in costly serialisation-deserialisation (which is a waste of developer time and CPU cycles) when moving data from one system to another. Systems that use or support Arrow can therefore transfer data at little to no cost.
Arrow is language agnostic and zero-copy, which brings significant performance benefits
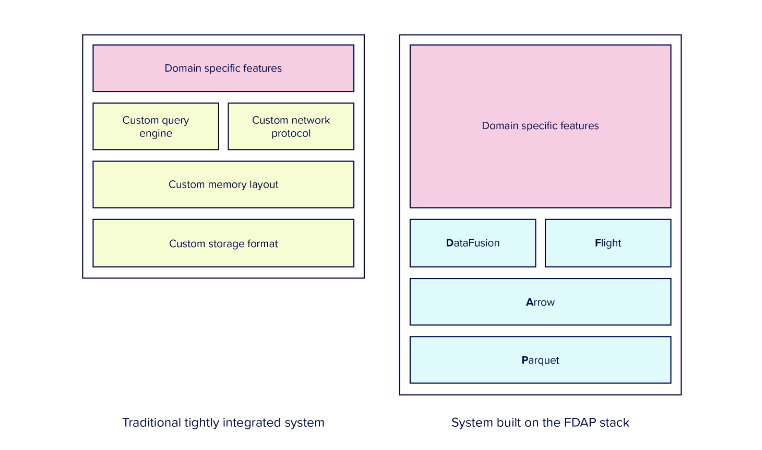
Arrow by itself is incredibly useful, and its appeal is greatly enhanced by other highly interoperable components built around it, such as DataFusion for the query engine or Flight for network data transfer. Arrow also works extremely well with the storage format Parquet. With the development of this interoperable open ecosystem, not only do we see a way forward for reduced fragmentation in the data stack, but also improved performance – which in turn is driving greater adoption of the Arrow ecosystem by vendors.
What’s happening now?
While we’ve seen data lakehouse vendors such as Dremio contributing to these projects since their inception and adopting them within their stack (Dremio uses Arrow, Iceberg and Parquet), we see early proof points that these are gaining traction. For example, InfluxDB 3.0, Polar Signal’s FrostDB, and GreptimeDB are new database solutions launched over the course of 2022-23 that have been built around the Arrow ecosystem.
InfluxDB’s visualisation of the FDAP Stack (Flight, DataFusion, Arrow, Parquet)
What’s next?
Going forward, we would expect more vendors to adopt interoperable open source components in their stacks. Within the database space, the Arrow ecosystem offers superior performance and has been consistently improving since its inception in 2016, adding more and more tooling that enhances functionality and interoperability. Because it is composed of highly interoperable elements, data engineers waste less time on managing different integrations and compatibilities, which frees them up to pursue other value-accretive tasks rather than undifferentiated heavy lifting. This in turn creates competitive advantages. As a result, we expect startups to build around interoperable open ecosystems where possible. Meanwhile, we expect enterprises to adopt interoperable open layers to unlock value across their tech stack (e.g. extracting value from both Databricks and Snowflake investments by leveraging Onetable).
Longevity and Evolvability
Given the rapid innovation cycles where today’s hottest technology is obsolete tomorrow, practitioners are increasingly focused on longevity and evolvability – technologies that have or are likely to withstand the test of time, but are also getting better and more performant for emerging use cases.
Object storage gets a new objective: becoming primary storage
The principle of Longevity and Evolvability is well illustrated by object storage. Object storage is a low cost storage option that is highly scalable, durable and available – but it has high latency. Historically, it was either used for backup and archive storage or the latency was circumvented with complex caching strategies. This changed in November 2023, when Amazon launched a new object storage class called S3 Express One Zone (EOZ) that features low latency access in a single availability zone. This means that you can enjoy the scalability of object storage WITH low latency and WITHOUT implementing complex caching strategies. Workloads and core persistence layers can now be built entirely around object storage which simplifies the architecture and code and leads to faster time to market. This is a major development for powering AI use cases, for which fast access to storage is key. That said, at the time of writing, individual API operations with S3 EOZ were 50% cheaper but storage was 8x more expensive than S3 Standard – which means startups will have to balance the trade-off between low latency and high storage cost. Nevertheless, object storage continues to get better, and we eagerly look forward to the developments that will likely follow EOZ.
What is past is prologue: PRQL and SQL
“Death, taxes, and SQL. Amid all of the growth, upheaval, and reinvention in the data industry over the last decade, the only durable consensus has been our appreciation of SQL.”
– Benn Stancil, CTO & Founder at Mode (link).
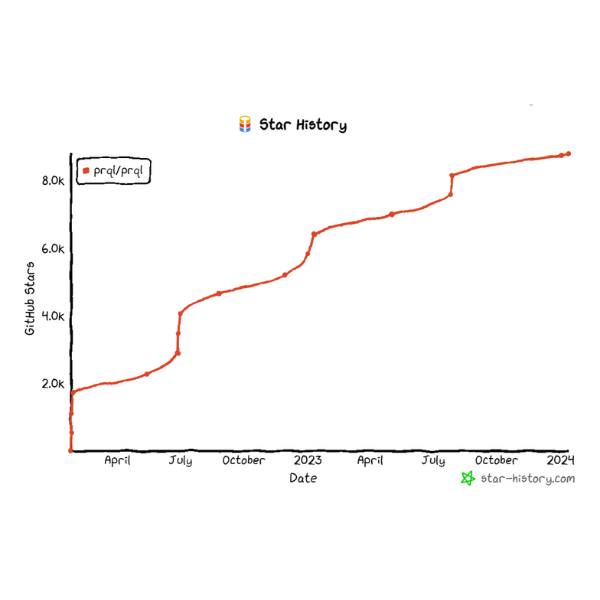
SQL has been the lingua franca for data since the 1970s – and this appears unlikely to change. In keeping with the principle of longevity and evolvability, we observed the growing popularity of new query languages such as PRQL (Pipelined Relational Query Language, pronounced “prequel”) and Malloy which compile to SQL, making querying simpler and more concise. In particular, PRQL was designed to serve the growing need of writing analytical queries, emphasising data transformations, development speed, and readability. Because PRQL can be compiled into most SQL dialects, it is portable and reusable. Additionally, it offers a pipelined execution model, so unlike a traditional query language which fetches the entire dataset and processes it as a whole, PRQL processes the data in smaller, manageable chunks and delivers results progressively as they become available.
Most attempts to replace SQL with another query language have been (justifiably) met with deep scepticism, not to mention rants like Erik Bernhardsson’s famous “I don’t want to learn your garbage query language.” What makes PRQL especially interesting is that it continues to gain traction, and this can be attributed to its open source nature (its creators stated that it will always remain open source and there will never be a commercial product), its compatibility with any database that uses SQL, its simplicity and its focus on analytics.
PRQL continues to gain traction, despite general scepticism around new query languages
PRQL represents an important innovation, in our view – not only because of the utility of the language itself, but also because of the principles that underpin it. It represents an Evolution of a Long-Lived technology (in this case, SQL) as well as demonstrates the importance of Interoperability and Openness.
What’s happening now?
Our conversations with practitioners suggest that three intertwined concerns dominate their thinking currently: (1) major architectural decisions are often hard to reverse, which means core technologies must be chosen in a way that support both current and future needs; (2) nobody knows what future needs might look like, with everything sharply accelerated in the Age of AI; and (3) there is a dizzying array of tools to choose from. The idea of longevity with evolvability is the solution here, as we illustrated through the example of Amazon S3 EOZ.
What’s next?
We believe startups can do two things: build their tech stacks on long-lived and evolvable technologies (such as object storage) and build solutions that evolve the long-lived (such as PRQL and Malloy).
Particularly as AI/ML workloads increase, we expect more startups to build their primary storage on object storage, given the step change that Amazon S3 EOZ represents.
In the “build solutions that evolve the long-lived” case, we admit that this isn’t an option available to all startups (you could be building something brand new, the likes of which the world has never seen before, and such groundbreaking innovation with commercial use cases are incredibly exciting!) but where a battle-hardened piece of technology is ubiquitous and familiar to practitioners (consequently difficult to displace), it is more pragmatic/easier to drive rapid adoption through “evolving the long-lived.” Familiarity is especially comforting in times of great change and upheaval (which we expect in the Age of AI) – a bit like how the first motor cars attached imitations of horse’s heads and advertisements likened cars to horses, to drive adoption.
Data-Centric AI and AI-Centric Data
Our research has highlighted a key feature of the Metamodern Data Stack to be what we call AI-Centric Data, which uses AI at every stage of the data lifecycle (generation, ingestion, integration, storage, transformation, serving). We see this driven by five main factors:
- Increased automation: Data engineering is 70% of the work in delivering AI use cases, and AI use cases are growing exponentially – resulting in a significant increase in data engineering workloads. In order to cope with this, we need higher levels of automation, something which AI itself can provide.
- Better utilisation of data: Unstructured data (text, images, video, audio etc.) contains a wealth of detail that could generate meaningful business insights – for instance, looking at customer reviews (text) along with customer support calls (audio) and product images (visual) to get a holistic understanding of customer experience. Over 80% of a company’s data is unstructured, yet less than 1% is currently analysed – though AI is going to change that.
- Improved quality: Without quality data, AI applications are meaningless. AI can be used for improving data collection at the source (e.g. simulating image capture settings to optimise for quality), for data curation (identifying the best data to train the AI model) and for data wrangling (identifying duplicates or errors).
- Enhanced privacy and security: AI is already used to generate synthetic data that protects the privacy of individuals, identify and mask sensitive customer information, as well as prevent, detect and respond to security incidents such as data leakages.
- Lower costs: AI helps to lower costs e.g. automatically detecting less frequently used data and moving it to cold storage which is cheaper, or using AI-driven data curation to inform decisions to reduce the amount of data collected upfront (less data collected = lower costs of processing, storing etc.).
What’s happening now?
We outline below some of the ways in AI is being used across the data lifecycle:
Data Generation: Besides using AI to generate synthetic datasets (artificially generated data to overcome issues around lack of data or data privacy concerns) or for automatically annotating/labelling unstructured data, there are other AI use cases that help improve the data generation process itself. To illustrate: Dotphoton generates machine-optimal synthetic image datasets with metrological precision. This process involves simulating variations in environmental and equipment settings to optimise data processing for downstream AI systems. For example, while more expensive camera systems can yield higher quality images, they also incur greater costs. Dotphoton’s data engines allow companies to identify the pareto front between data state and data cost for the best of both worlds: top AI system performance at the lowest possible cost.
Data Curation: With the growing focus on “better data” rather than “more data,” we expect data curation to see greater traction – and AI can be a big boon here. For instance, Lightly combines active- and self-supervised learning algorithms for data selection, and selects the subset of a company’s data that has the biggest impact on model accuracy. This allows the company to improve its model iteratively by using the best data for retraining. In fact, this can also shed light (pardon the pun) on a company’s data gathering process (a lot of data being collected may not be meaningful enough to train an accurate model), and drive a re-thinking of the data collection process.
Data Integration and Transformation: AI models can be leveraged to perform a variety of transformations on data (e.g. conditionals, complex multi-column joins, splits) and ensure that the data conforms to business rules, defined schema and quality standards. It can even be used for pipeline migration – this CNCF blog post talks about using LLMs and prompt engineering to automate the conversion of YAML scripts of existing Jenkins, Azure and GitLab pipelines to Tekton YAML scripts, making the pipeline migration process and adoption of newer technologies much simpler.
In particular, we are interested in AI-driven integration and transformation of unstructured data. Unstructured data is complex and exists in a variety of formats – not just image, video, and audio, but also industry-specific formats such as DICOM for medical imaging or .hdf5 for aerospace. Joining unstructured data sources with other data formats or datasets is particularly challenging – the integration is not just about bringing together different data types, but also the context and narrative underpinning them. For instance, looking at customer reviews (text) along with customer support calls (audio), product images (visual).
As such, there is greater momentum in AI-powered data transformation. For instance, Instill AI provides a no-code ETL pipeline called Versatile Data Pipeline that extracts unstructured data and uses AI to transform it into analysable or meaningful data representations, and Matillion announced that it is launching LLM-enabled pipelines. We also see AI being used in feature engineering (the process of creating a dataset for ML by changing existing features or deriving new features to improve model performance). For instance, Datarobot is using AI for automated feature engineering.
A different type of pipeline for information retrieval (and especially unstructured data) is that of Vector Compute, which applies machine learning to raw data to generate vector embeddings. This is where Vector Compute providers such as Superlinked* play a critical role, as its solutions turn data into vectors and improve the retrieval quality, by helping enterprises create better and more suitable vectors that are aligned with the requirements of their use-case, bringing in data from multiple sources instead of just a piece of text or an image.
Data Storage: The practise of AIOps (application of AI to automating IT operation management tasks) has been around for a while, and most data storage vendors (Dell, IBM, Pure Storage) offer AIOps solutions. Particularly for data storage, AIOps is used to assess data usage patterns or access frequency for intelligent workload placement (e.g. frequently accessed data on faster, more expensive storage and infrequently accessed data on cold storage). AI can also automate several data storage tasks, such as backup, archiving and replication, and troubleshoot data storage issues. Additionally, we see startups emerging in the space, such as DBtune and OtterTune, that provide solutions for AI-powered database tuning and performance optimisation.
Data Serving: Most BI/Visualisation incumbents such as Tableau, ThoughtSpot, Qlik, Domo have introduced AI-powered tools that allow users to surface key insights or create charts from data by asking questions in natural language. Another AI-powered way of serving data is through in-database machine learning solutions provided by MindsDB* which enable users to consume AI output straight from their native database (such as MongoDB, PostgreSQL) without having to construct complex ETL (Extract, Transform, Load) pipelines.
What’s next?
Using AI within the tech stack isn’t a new idea – practices such as AIOps, which use AI to monitor the performance and reliability of applications and hardware have been around for a while. However, our belief is that this will likely become more widespread across the data stack given the benefits we outlined earlier and the latest AI-powered innovations. For instance, some startups are focused on tackling the harder problems of multi-modal data transformation using AI.
While not an explicit stage of the data lifecycle (such as generation → ingestion → storage → transformation → serving) there are some considerations that are of paramount importance across the entire lifecycle, such as data governance, data security and data privacy. It would be remiss of us not to discuss this as thoroughly as it deserves, and we will explore this in greater detail in our next blog post.
Decentralisation and Unification
Over the last few years there has been significant hype and controversy around the data mesh, which has 4 core principles: (1) decentralised domain ownership of data; (2) data as a product; (3) self-serve data platform; and (4) federated computational governance.
Given the proliferation of data sources, data consumers and data use cases (especially in the Age of AI), it stands to reason that centralised data teams would be inundated with requests; moving to decentralised systems would distribute the workload and enhance scalability. These centralised data teams may lack the domain expertise needed to understand the context around the data, in which case it makes sense to move the data-related decisions into the hands of business users who best understand them. With each domain responsible for the quality of the data it serves as products, clear accountability is created. Additionally, there is increasing regulatory focus around data privacy and security (not to mention data sovereignty)- in which case decentralisation becomes a necessity and not a choice.
For such a decentralised system to work, it needs to be underpinned by standardisation, interoperability and strong governance… all of this sounds fairly non-controversial. So what’s the issue with data mesh?
It primarily has to do with the extent of decentralisation in the data mesh architecture, and challenges with integration, interoperability and governance. According to the definition of Data Mesh as outlined by Zhamak Dehghani, it is a purely decentralised architecture with no data warehouse. The responsibility of integrating the data isn’t set aside, but it is distributed across multiple domains – which could potentially create new issues.
“What’s kind of neglected in Data Mesh is the amount of effort that you want to do if you go with a full decentralization when it comes, for example, to master data management.”
– Mahmoud Yassin, Lead Data Architect at ABN AMRO
(Data Mesh Radio episode #103 “4 Years of Learnings on Decentralized Data: ABN AMRO’s Data Mesh Journey”)
What’s happening now?
Enterprises have come up with their own modifications to the data mesh. For instance, they may have a local data product owner within the domain who is responsible for the data, but they are responsible for sending that data to the company’s centralised data infrastructure. The data within the central platform could be logically separated by domain, permissibility, classes and use cases. Thus there is a central team that not only provides the infrastructure, but also takes data provided from all the different data owners and aggregates it into unified datasets that can be used across domains. Independent of the data decentralisation trends, other technologies which would support “unification” in a decentralised environment are gaining traction – such as event streaming and streaming processing, data contracts, data catalogs, and semantic layers.
“So we are not doing a perfect data mesh by the books, but we have overtaken a lot of principles and ideas and then translated them to our needs.”
– Moritz Heimpel, Head of Analytics and AI Enablement at Siemens
(The Analytics Engineering Podcast episode “Data Mesh Architecture at Large Enterprises”)
“We’ve seen customers do a blend where rather than data mesh, if you typically look at that sort of definition, it really doesn’t have a central team. And I think that’s wrong. So what I’ve seen customers really be successful in is implementing a hub and spoke style.”
– Dave Mariani, CTO & Founder at AtScale
(Monday Morning Data Chat episode #124 “The Rise of the Semantic Layer in the Modern Data Stack”)
Regardless of whether enterprises choose to implement a data mesh in the strictest sense or a loose interpretation of it (we expect more of the latter), we see a lot of merit in decentralising some ownership of data to domain-specific teams, and treating data as products.
Moving on to the practicalities of building a data mesh, one way to do so is to use event streaming. Events represent something happening, or a change in state (e.g. a customer clicking on a link, or placing an order), while event streams are a series of events ordered by time, that flow from the systems that produce the data to systems that consume the data (e.g. the email service that confirms the customer order has been placed, or the service that updates the inventory post receiving the order). Event streams therefore publish real time data to multiple teams with unique needs, and because these streams are stored, consumers can access both historical and real-time data. This combined with stream processing (which analyses, transforms and enhances data in event streams) enables powerful real-time AI applications for anything from fraud detection to instantaneous personalisation.
This is where companies such as Quix* help, by providing a complete solution for building, deploying, and monitoring event stream processing applications. Quix makes it easier for domain engineers to self-serve access to streaming data and build data products. With a low barrier to entry and a high ceiling, Python engineers can reuse batch processing techniques to transform data whilst also leveraging the Python ecosystem to import ML models and libraries for more complex real-time ML and AI use cases. Of course, event streaming and stream processing applications can be applied to centralised or decentralised architectures, though we see it as particularly important for the latter, and especially for AI applications.
We also see data decentralisation as being facilitated by certain other developments that occurred over the course of 2023, such as the growing adoption of data contracts. In essence, data contracts bridge the communication gaps between data producers and data consumers by outlining the standards the data is expected to meet, who is responsible for ensuring the data meets those standards, the schema (structure) and semantics (meaning) of the data, SLAs for delivery, access and data quality as well as the policies governing the data. Additionally, data contracts can include specifications around interoperability of different data products. We couldn’t express it better than Yali Sassoon (Co-Founder and CPO at Snowplow*) in his article about ‘What is, and what isn’t, a data contract‘.
In a related development, in November 2023, The Linux Foundation announced Bitol, the Open Data Contract Standard (ODCS), as its latest Sandbox project. ODCS traces its origins to the data contract template that was used to implement Data Mesh at PayPal. Because ODCS leverages YAML, it can be easily versioned and governed. Tying back to our earlier discussion around Interoperability and Openness, the creation of standards and templates for data contracts should drive higher adoption, and we believe it will be a key enabler of data decentralisation.
Beyond data contracts, you need another unifying elements to make data decentralisation work, such as data catalogs, data modelling, semantic layers and so on. Data catalogs contain metadata (such as structure, format, location, dependencies) to enable data discovery and data ownership management, while semantic layers capture the business meaning of data (e.g. “what do you mean by a customer? Someone who purchased something from us in the last 90 days? Or someone who has ever purchased anything from us?”).
This is where startups such as Ellie are helping enterprises apply business context to data through data modelling and data collaboration tools. In particular, Ellie enables non-technical business users to extract value from the more technically-oriented data catalogs through a simple user interface that captures business intention and links it with data.
What’s next?
As workloads and regulatory pressures increase, we see the move to data decentralisation as inevitable; however, the degree of decentralisation would vary depending on the organisation’s natural ways of working. We believe that enterprises and startups should incorporate “unification” elements long before the actual decentralisation starts, to ease the process and make the transition easier.
Pragmatism and Idealism
Although many companies would like to adopt newer, better technologies rapidly, in practice they are slow to replace mission-critical parts of the tech stack given fears around disrupting business activities. Let us illustrate this with the example of databases. Practitioners dislike migrating from old databases to new ones, given schema changes, changes to indexes, re-writing queries and data manipulation expressions… and the list goes on.
Change is slow to come: Oracle, PostgreSQL, MongoDB etc continue to dominate, even as newer solutions gain traction
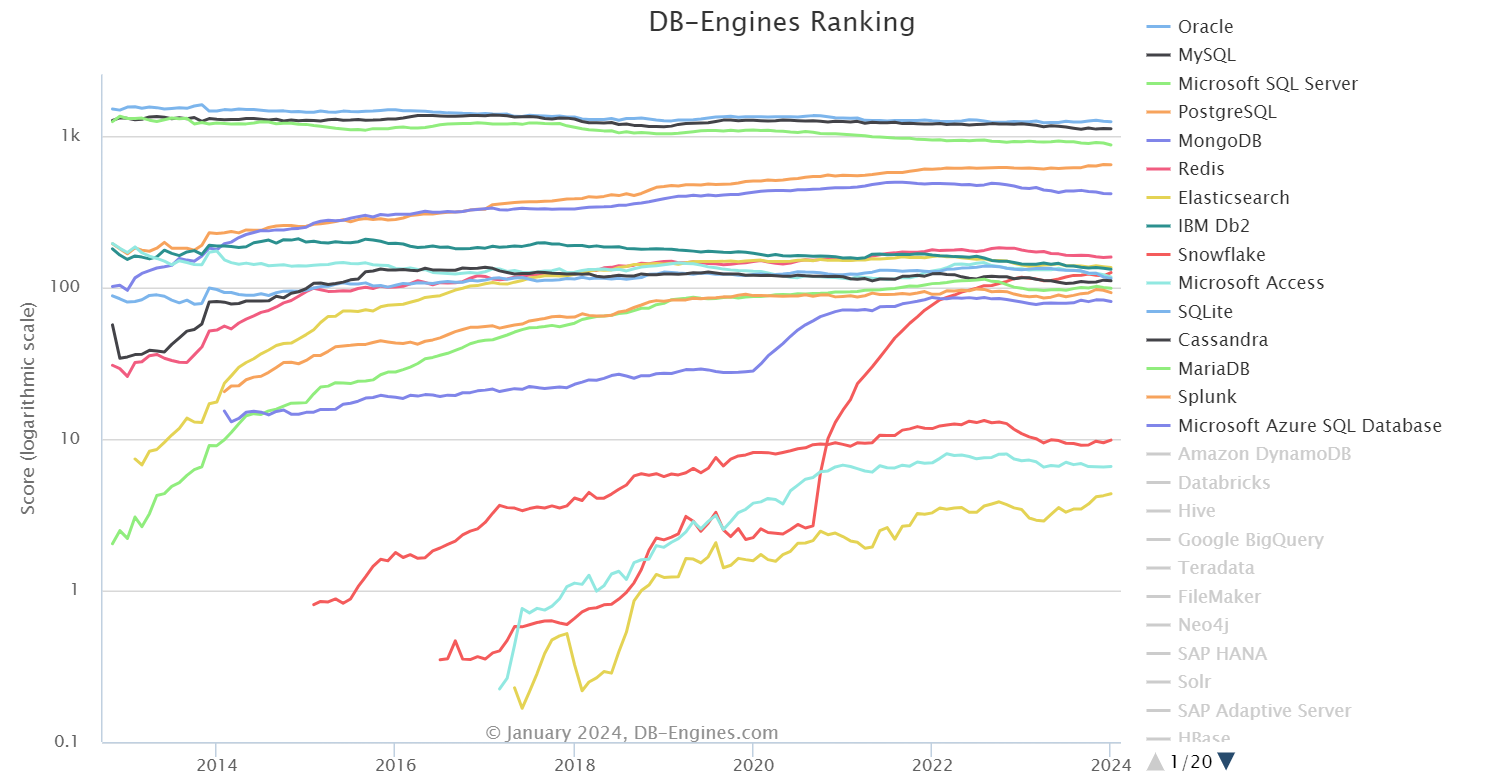
Rather than conform to the unrealistic idea that enterprises will rapidly migrate all their data to the new database, the idea of “pragmatic idealism” acknowledges that enterprises are reluctant to do so, and instead creates a solution that lets enterprises use their existing tools yet at the same time take advantage of the latest technologies. For instance, Quesma is a lightweight compatibility and translation layer that connects an enterprise’s apps with both its legacy and new databases. It effectively unbundles the app stack from the database engine by introducing a smart database gateway/proxy in between, which translates the database queries into the format of the new database and enables double read and double write. In this manner, enterprises can adopt new database technologies for new use cases without migrating from old ones. Similarly, based on this principle of helping enterprises use existing technologies for new use cases, SuperDuperDB helps bring AI models to an enterprise’s existing database – without needing specialised vector databases.
The fundamental idea here is to focus on the existing and upcoming – for instance, a database gateway that decouples the app stack from the database engine wouldn’t just work with what is legacy and new as of today – it would also look at today’s latest technologies that will become obsolete in the future and provide a way to work with that alongside newer futuristic technologies. That’s why we believe pragmatism is a good starting point.
Our Evolving Thoughts
The common thread running through all of this is automation through AI, interoperability, and longevity with evolvability. Much of this is underpinned by openness, and to that end we’re excited by developments such as the Arrow ecosystem, PRQL, Onetable and Bitol.
Our idea of the Metamodern Data Stack is an evolving one, and we would love to hear your thoughts on the technologies you are most excited about, what you are building in the space, and what your hopes are for the future of data engineering.
*MindsDB, Quix, Snowplow and Superlinked are MMC-backed companies.
We published The Metamodern Data Stack as the first part of our series exploring the challenges around AI adoption. The subsequent parts of our series will be focused on key issues such as data privacy and security, emerging modelling paradigms, and domain-specific applications of AI. We’re also building out our map of European startups operating in the Data Infrastructure and Enterprise AI space – if you think your business should be on it, please get in touch.
Post script: Why call it “Metamodern”?
We borrowed from the world of cultural philosophy (Modern → Postmodern → Metamodern). Modernism is characterised by enthusiasm around science, development, progress, and grand visions, while Postmodernism is distinguished by cynicism regarding the same. Metamodernism oscillates between modernist enthusiasm and postmodernist scepticism. Metamodernism acknowledges things for what they are, but at the same time believes that things can be made better. Similarly, we believe that while the modern data stack is characterised by high levels of complexity and fragmentation, it can be made better through developments such as Onetable or Bitol. Metamodernism is therefore characterised by “pragmatic idealism” – technical debt is never going away, but we can always find new ways to make the most of existing technologies whilst incorporating innovative new capabilities.
Related Articles
The Who’s Who in Responsible AI
In Part I of our series on Responsible AI, we explored the fascinating reasons…...

Responsible AI: Why it’s so hard, and why we should care about it
Legally murky (and vigilante) applications of AI aside, we see these powerful models being…...

Series 4: Ep 3. Using data and AI to drive better decision-making
MMC Partner, Simon Menashy, interviews David Benigson, founder and CEO of Signal AI -…...

The Bloomberg of energy: Why we invested in Modo Energy
The energy storage problem While sources like solar and wind are less carbon-intensive, they…...

Six barriers to AI adoption – and what enterprises can do about them
While political leaders debate on Terminator-esque AI paradigms, enterprises are more concerned about their…...

What kind of billion-dollar AI company are you building?
Simon Menashy, Partner at MMC, shares his view as an investor of where…...
Supercritical’s carbon removal marketplace raises $13m Series A
Supercritical aims to accelerate the urgent scaling of carbon removal technologies by aggregating business demand…...
