As a research-led VC, MMC strives to provide deeper expertise and insight into the emerging technologies and trends that will reshape our society over the coming decades, such as TechBio.
Charlotte and Mira break down MMC’s investment thesis in this compelling space.
Biotech, healthtech, and medtech are some of the terms we are used to hearing when discussing technological advancements in the bioscience space. More recently, however, the term ‘TechBio’ is being used to better differentiate and categorise companies blending cutting-edge technologies, computational methods, and data-driven, engineering-first approaches applied to biological research and drug development.
Within the TechBio landscape, computational biology plays a crucial role in various aspects, including advancements in genomics research, drug discovery and development, personalised medicine, and systems biology. It involves the application of computer science, mathematics, statistics, and bioinformatics, and has become an integral part of systems biology research.
As a technology investor, we at MMC have decided to break down our investment thesis in the space. We believe the next generation of toolkits is emerging, empowering scientists and accelerating their research and development efforts.
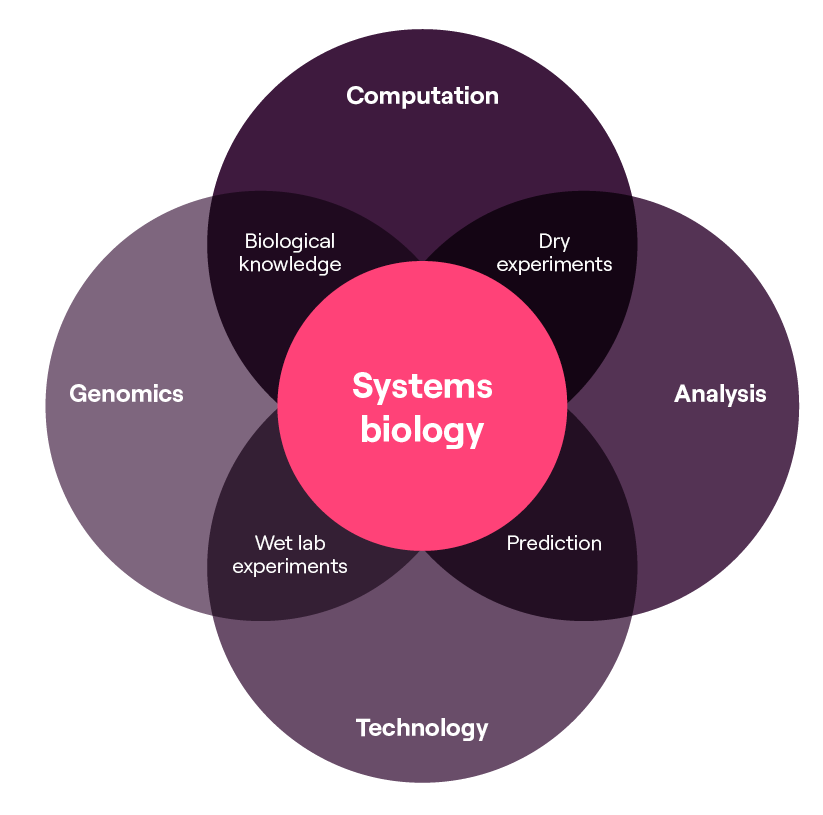
Why now?
The unprecedented scientific progress and boundless technological innovations we see today are setting the stage for a new wave of opportunities for TechBio start-ups, driven by the explosive convergence of industry trends and the rise of computational biology.
Moreover, the digitisation and virtualisation of samples and research findings, facilitated by cloud-based platforms, have revolutionised data-sharing capabilities. This allows for the seamless exchange of ever-larger datasets across the globe, fostering collaboration and enabling comprehensive analyses on an unprecedented scale.
Despite the increase in the data, industry professionals have confirmed that although biopharma is collecting 7x more investigational drug data than 20 years ago, drugs are not getting to market faster nor with a higher hit rate. While technologies are improving at pace, the technologies across the drug discovery paradigm still need to successfully translate this data into insights.
Moreover, the digitisation and virtualisation of samples and research findings, facilitated by cloud-based platforms, have revolutionised data-sharing capabilities. This allows for the seamless exchange of ever-larger datasets across the globe, fostering collaboration and enabling comprehensive analyses on an unprecedented scale.
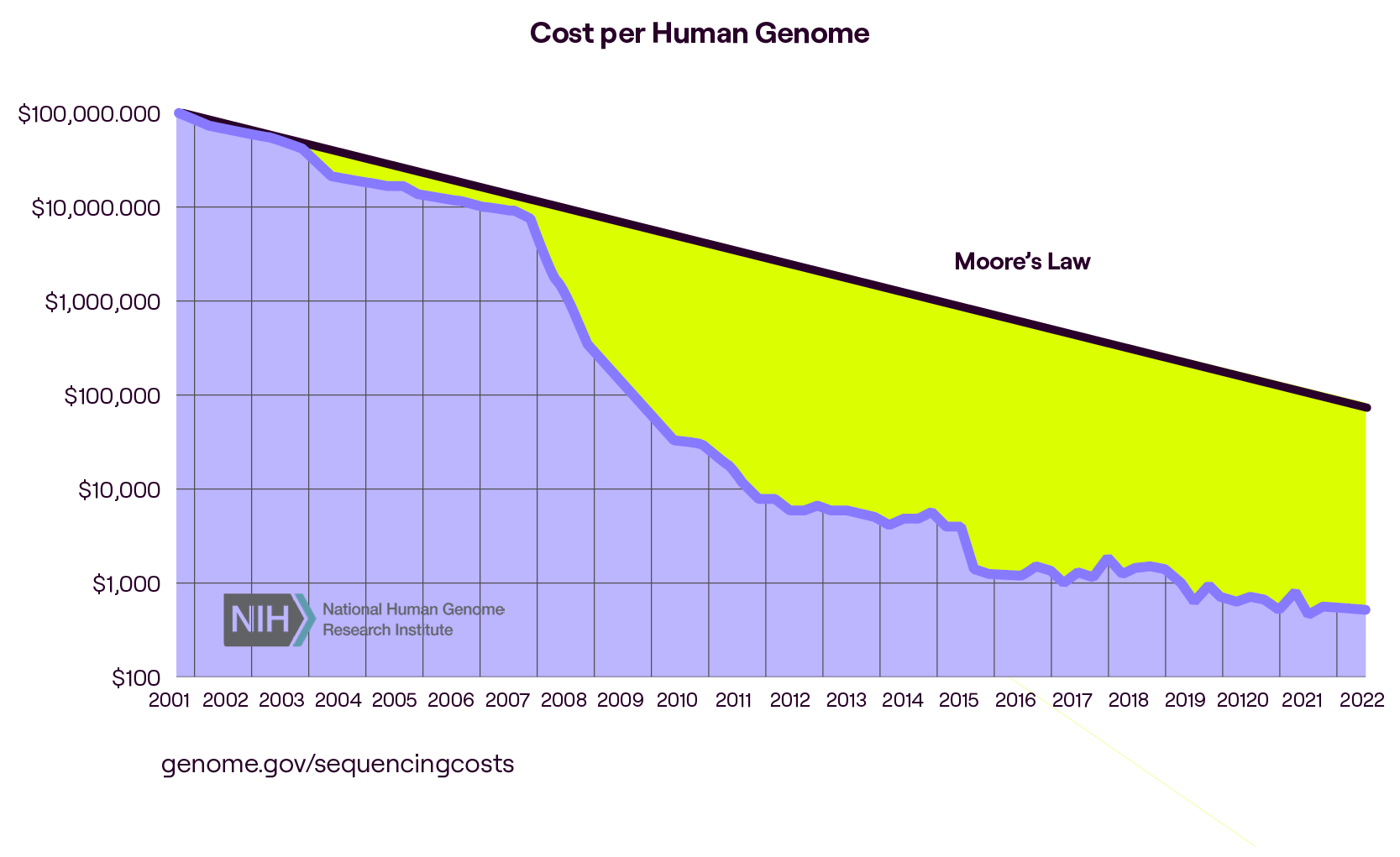
Despite the increase in the data, industry professionals have confirmed that although biopharma is collecting 7x more investigational drug data than 20 years ago, drugs are not getting to market faster nor with a higher hit rate. While technologies are improving at pace, the technologies across the drug discovery paradigm still need to successfully translate this data into insights.
We have observed a significant shift in mindset within the industry. Companies have embraced the data/engineering and statistical perspective, transforming traditional research and development (R&D) processes. Instead of starting with a hypothesis and conducting experiments to test it, start-ups are flipping the script and adopting a data-first approach to identify new targets. They begin by mining vast datasets (the most valuable ones being self-generated) for insights, using sophisticated algorithms to uncover patterns and connections that may have otherwise gone unnoticed. Whilst a promising start, we believe this needs to be combined with later-stage human-derived and clinical biomarker data, particularly when it comes to deepening our understanding of disease pathology.
In this dynamic environment, TechBio start-ups have the opportunity to disrupt conventional practices by leveraging the power of data, advanced analytics, ML/AI algorithms, and cloud computing, which can drive innovation at the intersection of technology and biology. These advancements can optimise personalised treatment and accelerate various stages of the drug development pipeline.
Market map
As the intersection of technology and biology continues to shape the future of the life sciences and drug development industries, we need to understand the evolving market landscape and identify key segments of interest.
We have identified five distinct segments, each targeting different aspects of the life sciences tech stack, ranging from lab automation, data generation and management, analysis, to clinical trial optimisation.
We noticed that while some companies focus on offering recurring Software-as-a-Service (SaaS) models for data infrastructure and management, the majority adopt more varied business models, which combine elements of SaaS, fee-based services, and strategic partnerships with pharmaceutical companies where revenue is linked to the upside potential (such as positive trial outcomes or value-sharing arrangements).

Following this analysis, we have distilled the market map into two primary segments that are of particular interest to MMC:
- Lab automation, Data Infrastructure and Analysis
- Next-Generation AI Drug Discovery Platforms
A third segment includes biotech companies that operate across the entire spectrum of drug development, more akin to the traditional model. While these companies fall outside the immediate scope of our analysis, they’ll play a significant role in shaping the future of the life sciences industry.
In the following sections, we will delve deeper into these two key segments, exploring the emerging trends, notable players, and investment opportunities within each domain.
Deep dive #1: Lab Automation & Data Infrastructure and Analysis
Unlocking the power of bioinformatics for large-scale data analysis
Bioinformatics, a field focused on managing and interpreting vast amounts of biological data, has become a critical bottleneck in harnessing the full potential of Next-Generation Sequencing (NGS) technology. The exponential growth in “omics” data necessitates the use of bioinformatics tools across various scientific disciplines, including wet lab biologists who lack advanced bioinformatics skills. However, this is changing with many biologists teaching themselves basic computational skills.
The market lacks advanced tools for NGS data analysis, such as annotation, alignment, and identification of meaningful patterns. Most existing solutions today are legacy systems, custom scripts deployed on on-premise servers, or open-source tools, which are widely regarded as the gold standard by scientists despite being fragmented.
There is a pressing need for a transformation in the bioinformatics tech stack, presenting an opportunity for innovative start-ups such as Latch Bio, that can efficiently standardise and scale data workflows to collect and curate complex data for downstream analysis. Ultimately, many early-stage challenges in bioinformatics are data management and interpretation problems, which can be approached as engineering problems. This realisation is the driving force behind companies like Lamin.ai, which is building better data infrastructure for R&D teams of any size.
Recognising the widely adopted model among scientists, open-source platforms are also experiencing a notable transformation to meet the changing needs of the evolving bioinformatics field. This trend aligns with the broader rise of open-source software, which has gained popularity among the wider community of software developers and data engineers seeking cost-effective and scalable solutions. Companies like Nextflow, are at the forefront of this movement, providing scalable and reproducible computational workflows specifically designed for bioinformatics analysis.
Democratising data engineering tasks in the lab
Traditionally, wet lab scientists heavily rely on bioinformaticians to handle unstructured data from sequencers or public datasets. This involves performing quality assurance, running custom scripts, and using open-source tools to narrow down areas of interest. However, there is a rising demand for democratising access to bioinformatics expertise and empowering wet lab scientists to perform the relatively simple parts of the analysis. It is possible achieving this through user-friendly graphical interfaces (GUIs) and the introduction of automation for downstream processes. A good example is Pipe Bio, a platform that enables wet lab scientists to analyse and manage DNA sequencing data without needing support from bioinformaticians or programmers.
Adopting cloud technologies in research and development (R&D) introduces new challenges as scientists spend significant time converting data formats, transferring data between applications, manipulating tables, aggregating statistics, and visualising data to extract insights. Addressing these challenges can unlock substantial value in the workflow, resulting in improved accuracy, efficient utilisation of expensive bioinformatics expertise for novel and complex tasks, and, most importantly, significant time-saving. According to McKinsey, pharmaceutical companies can bring medicines to the market more than 500 days faster and reduce costs by 25%, mainly through automated processes.
Meeting diverse buyer and user profiles
To effectively navigate the landscape of lab operations and data infrastructure, it is essential to grasp the distinct motivations, priorities, budgets, and technical proficiency of the various buyer and user profiles. These encompass large pharmaceutical companies, academics, smaller biotech firms, as well as wet and dry lab scientists.
Large pharma companies often possess in-house teams that develop their own platforms with support from bioinformatics experts, but while collaboration and reuse are prioritised in these expansive operations, the tooling employed may not always be at the cutting edge. Conversely, smaller biotech firms, typically comprising 50-80 individuals with fewer bioinformaticians (at a ratio of 1:20), seek workflow tools that can better serve their biologists.
Dry lab scientists, including bioinformaticians and computational biologists, strive for standardisation in their workflow, particularly at the initial stages where most of their time is spent. They adopt a detailed, developer-like approach to deconstruct visualisations and construct custom tools from scratch. For these professionals, the extensibility of the platform, integration of diverse data sources and tools, and robust data testing capabilities are crucial. In contrast, wet lab scientists prioritise platforms that automate annotation and downstream visualisation processes, equipping them with fundamental bioinformatics skills.
Irrespective of the organisation’s size, a team with extensive domain expertise and the capacity to expand the platform’s capabilities to provide comprehensive end-to-end solutions is essential for effectively selling to technical buyers in this rapidly evolving industry.
In terms of purchasing decisions, scientists search for “best of breed” solutions that cover more bases rather than an inferior “off-the-shelf” platform. The pricing power of a tool is often linked to its complexity, but fostering loyalty among price-sensitive users is possible. For instance, scientists in academic institutions and small biotech companies, who prioritise platforms capable of storing and capturing structured genetic data, may be more conscious of pricing. However, if they have previous experience using a platform in other organisations, they are more inclined to develop a compelling business case to justify the purchase of these tools.
What’s next?
At MMC, we anticipate a significant expansion in the scientist toolkit as biopharma and scientists seek more efficient ways to collaborate and standardise data pipelines, ultimately enhancing the efficacy of life sciences R&D. Just as engineering experienced a revolution in workflow standardisation, we foresee a similar trend impacting bioinformatics.
We believe that the winners in this evolving landscape will be teams that possess both technical expertise and a strong product focus. They will actively listen to customer needs, incorporating training requests and desired product features while recognising the importance of allowing customisation on their platform. Considering the complexity of potential features, solutions, and open-source simulations, an extensible platform that can seamlessly integrate various best-of-breed solutions is crucial. This flexibility empowers developers, data scientists, and bioinformaticians to delve into the code and tailor the platform to their specific requirements.
The viability of building a significant fee-for-service (SaaS) business in this space is still debatable. However, companies like Benchling, a category leader in driving product-led growth (PLG) for scientists, provide confidence in a successful SaaS model. Conversely, many companies that initially started with fee-for-service models are now exploring revenue upside through royalties, exemplified by the case of Schrödinger.
At MMC, we find this emerging market incredibly exciting. Based on our bottom-up analysis, which considers the increasing number of scientists, we project that this market could reach $10 billion by 2030 (EU and US markets only). We are actively seeking conversations with founders operating in this space as we recognise the tremendous opportunities and potential for growth.
Deep dive #2: Next generation of AI drug discovery platforms
The challenge of siloed data
To comprehend the path ahead, we must examine the starting point. In the field of biopharma, a prevailing concern revolves around the issue of data. Biopharmaceutical companies consider data as the cornerstone of their intellectual property (IP), resulting in a significant portion of industry data being confined within silos. This fragmented data landscape poses a hindrance as the complexity of diseases targeted by biopharma surpasses the available data’s capacity to support them adequately. Additionally, many companies lack the talent required to extract optimal insights from their data, assuming it is of sufficient quality in the first place.
Just as the Genome project in 2000 revolutionised biopharma by enabling the identification of new drug targets and inspiring ground-breaking initiatives like the UK Biobank through public datasets, we anticipate a similar wave of innovation when the obstacles of siloed data are overcome. This progress will serve as a catalyst for further advancements in data-driven drug discovery, paving the way for transformative breakthroughs.
The first generation of AI-enabled drug development: A paradigm shift in biopharma
In the world of drug discovery, the rise of artificial intelligence (AI) was like a ray of hope, offering the promise of revolutionising the entire process. The first generation of AI-enabled drug discovery (AIDD) companies, including Exscientia and Benevolent emerged as pioneers in this field by leveraging AI algorithms to analyse vast public datasets or proprietary data from biopharmaceutical companies. Others, such as Owkin, are paving the way by using federated AI to draw insights from data sitting in the silos to build better disease models and identify new biomarkers.
Integrating AI into the drug discovery process marked a significant departure from the traditional phenotype-driven approach, where candidates were screened based on known diseases and their symptom changes. It introduced a data-driven approach focused on identifying new targets and predicting properties and outcomes by analysing large, diverse datasets. This shift was met with excitement as biopharmaceutical companies recognised the potential for AI to accelerate their progress and became aware that AI was a “must-have” to remain competitive in the industry.
However, hiring top talent and data scientists in the biopharma industry remains a challenge. Instead, biopharma companies are accessing this talent through strategic partnerships with leading tech companies (e.g. Novartis partnering with Microsoft’s in 2021), acquiring AI capability (e.g. Genentech/Roche acquiring Prescient Design in 2021), or acquiring smaller AI companies that complement another one’s existing tech stack (e.g. Recursion acquiring Valence and Cyclica in 2023). We anticipate a continued wave of strategic collaborations and acquisitions as biopharma companies strive to unlock the full potential of AI-driven technologies.
Despite the initial enthusiasm surrounding AI-driven drug discovery, it has become increasingly clear that AI alone is not a silver bullet that guarantees success. The drug discovery process is inherently complex, spanning an average of 10 years from target identification to drug approval. Many pioneering AIDD companies have been active for nearly a decade, yet we have not witnessed the approval of drugs solely supported by AI-driven approaches. This realisation prompted the industry to acknowledge the need for a collection of technologies, rather than relying solely on AI, to enhance the drug discovery process in the long run.
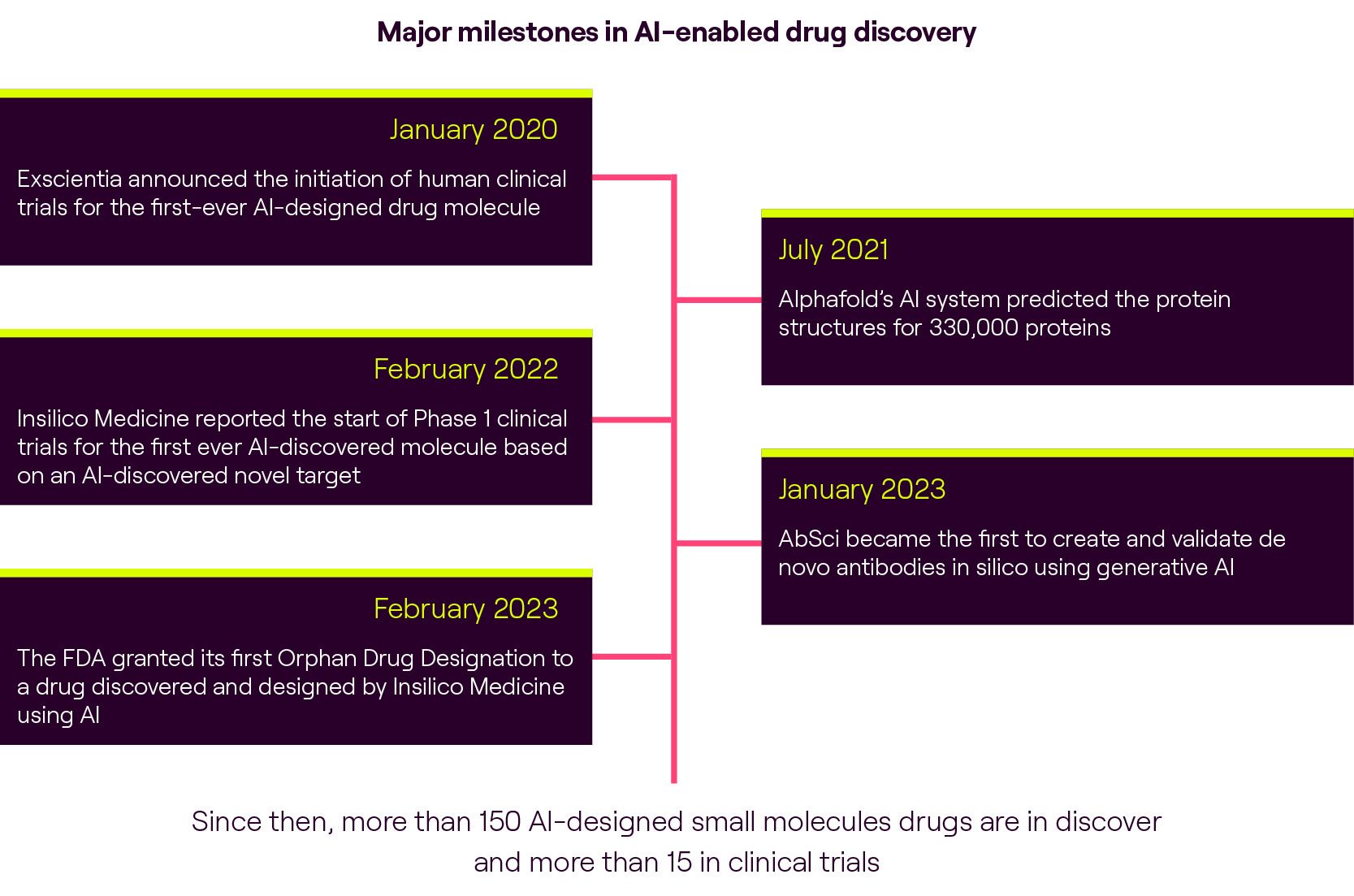
One of the critical limitations of the first-generation AIDD approaches is the heavy reliance on public or incomplete datasets that may not be readily applicable to machine learning (ML) algorithms. To address this challenge, a second generation of AIDD companies has emerged focusing on data generation and curation, ensuring the availability of high-quality, comprehensive datasets. These companies have also learned that feedback loops, achieved through constant iteration and testing of findings in the wet lab, are crucial to testing new hypotheses and bringing a granular, “data-driven” approach back to seeing the big picture.
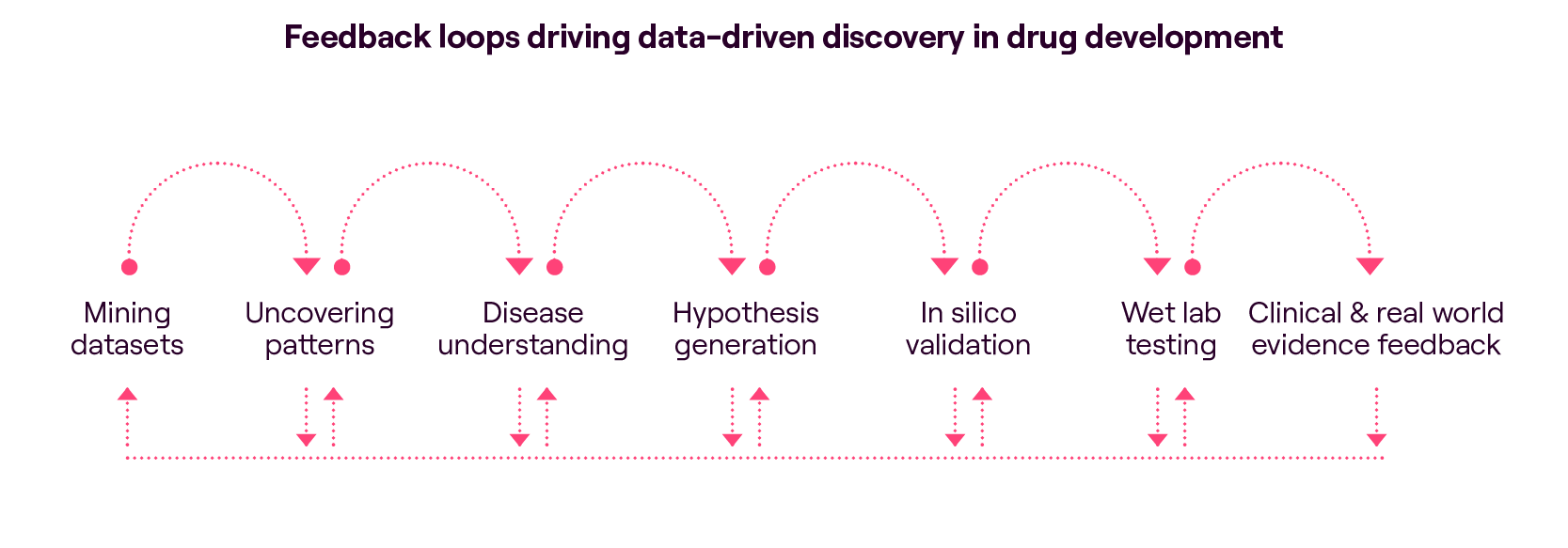
Fuelling the success of second-generation AIDD companies
The success of second-generation AI-enabled drug discovery (AIDD) companies can be attributed to several converging trends shaping the drug development landscape. These trends are driving advancements in data generation, human disease modelling, regulatory considerations, and the emergence of generative AI technologies.
One key factor contributing to the success of these companies is the increasing ability to generate multi-“omic” data. Recent advancements in sequencing technologies such as 10x Genomics, Illumina, and Berkeley Lights have made detecting not just genes, but RNA, proteins, and other cellular products more economically viable. This wealth of multi-“omic” data enables scientists to build a more comprehensive understanding of complex, multi-factorial diseases. Start-ups like MultiOmic and CardiaTec are leveraging this data to gain insights into metabolic diseases and cardiovascular conditions. By integrating multi-“omic” data, scientists can identify novel targets and mechanisms manifesting these challenging diseases.
Another significant development is the emergence of start-ups focused on creating improved human models of diseases and generating human-derived data. At the forefront of this innovation are companies like Pear Bio and Turbine AI (creating cancer models), Ochre Bio (creating liver models), and Xilis (creating organoids). These human disease models provide a closer approximation of human physiology and disease pathology, enabling scientists to simulate the disease phenotype more accurately and improve the testing of drug candidates. With improved human models, data-driven target selection becomes more relevant and effective, moving away from constant iterative trial and error at a single or few gene levels.
Regulatory changes also favour the adoption of more effective human-derived models for testing new drug targets. In a significant shift, the FDA announced in 2022 that animal trials would no longer be required for every new drug approval in an attempt to address ethical issues and improve the efficacy of new drugs. While the full realisation of these changes will take time and not fully replace animal trials in the medium term, they represent a positive step forward in mitigating the decline in available and accurate human data as a drug target progresses towards clinical trials.
Additionally, as data is an expensive asset to generate to a high standard, there is considerable buzz around the promise of generative AI in drug discovery and its ability to reduce the cost and time associated with data generation by simulating large amounts of synthetic data. Companies like Cradle.ai are leveraging generative AI to improve predictions of protein structures, while others like Syntho and Replica Analytics (acquired by real-world evidence firm Aetion in 2022) are creating privacy-protected synthetic data to improve testing, research, and analysis.
What are buyers looking for?
When evaluating partnerships or adopting new software solutions, buyers aim to accelerate the drug discovery process and maximise their return on investment (ROI), primarily focused on time saved rather than financial considerations. Indeed, by saving time, buyers can sell the drug while it is still under patent protection, which is a far greater financial consideration and represents additional billions of revenues.
For consideration, the main ROI for buying new software solutions is full-time equivalent (FTE) hours. For example, traditional high-throughput screening efforts may require a team of at least five individuals to operate and maintain equipment for several weeks. In contrast, computationally assisted virtual screening can be completed in approximately a week, with most of the work performed by the computer, even with wet lab validation.
Managing partnerships and navigating intellectual property (IP) ownership rights also play a significant role for buyers. Buyers seek multi-disciplinary teams with expertise in partnering with pharmaceutical companies and value peer-reviewed publications that prove the technology’s effectiveness and reliability. Furthermore, buyers are particularly interested in teams that possess experience in navigating complex commercial arrangements that are mutually beneficial for both parties. A crucial aspect of these negotiations revolves around shared versus proprietary IP, as pharmaceutical companies are keen on protecting their interests considering their extensive experience in IP acquisition to expand their pipelines. Therefore, while start-up companies may find the allure of IP ownership and potential royalties appealing, it is essential to carefully consider how these models would affect potential strategic partnerships and how this drives their longer-term business model as a technology platform on one end of the scale vs full stack biotech on the other.
What’s next?
Although AI algorithms can provide valuable insights, there is always doubt whether virtual screening accurately represents what would occur in a real-world setting. This doubt will persist until one of the AI-developed drugs currently undergoing clinical trials gets approved. This challenge prompts buyers to seek assurance and validation methodologies that bridge the gap between virtual and experimental results, providing confidence in the effectiveness of AI-driven predictions.
Related Articles
Series 4: Ep 2. Accelerating the future of personalised medicine
MMC Principal, Charlotte Barttelot, leads our focus on data-driven health investments. In this episode,…...

How generative AI can help improve patient outcomes
Artificial intelligence (AI) is one of the key technological developments of the 21st century,…...
MultiOmic Health Secures $6.2 Million
MMC was proud to participate in the round, alongside Hoxton Ventures, Ada Ventures, and Verve Ventures. Existing…...

MMC backs wawa fertility
The fertility industry is operating on a broken model, where the chance of success…...

Deeptech start-up ImVitro raises $2.5m
ImVitro’s team is united by the vision to create an easier path to parenthood…...
How XUND is looking to solve one of the biggest problems in healthcare
Digital healthcare is a rapidly growing sector. Telehealth utilisation is 38 times higher than…...

Technological revolution in mental health
Challenges associated with mental health were exacerbated by the COVID-19 pandemic – with depression…...

XUND raises €6m for its AI-powered medical API
XUND wants to revolutionize tomorrow’s healthcare by delivering evidence-based solutions to patients and healthcare professionals…...
